
Landslide Susceptibility Evaluation Based on Combined DBSCAN Cluster Sampling and SVM Classification
-
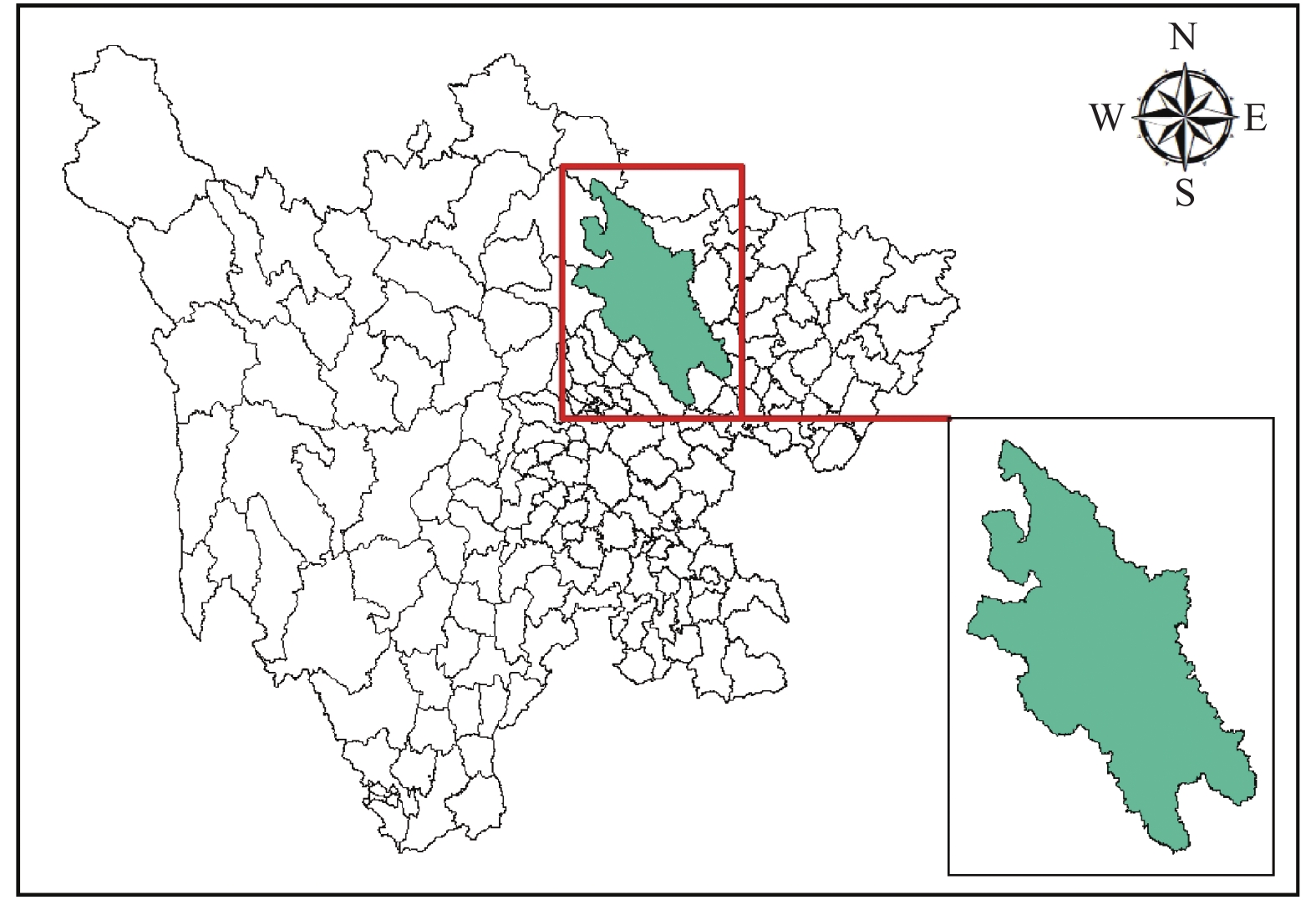
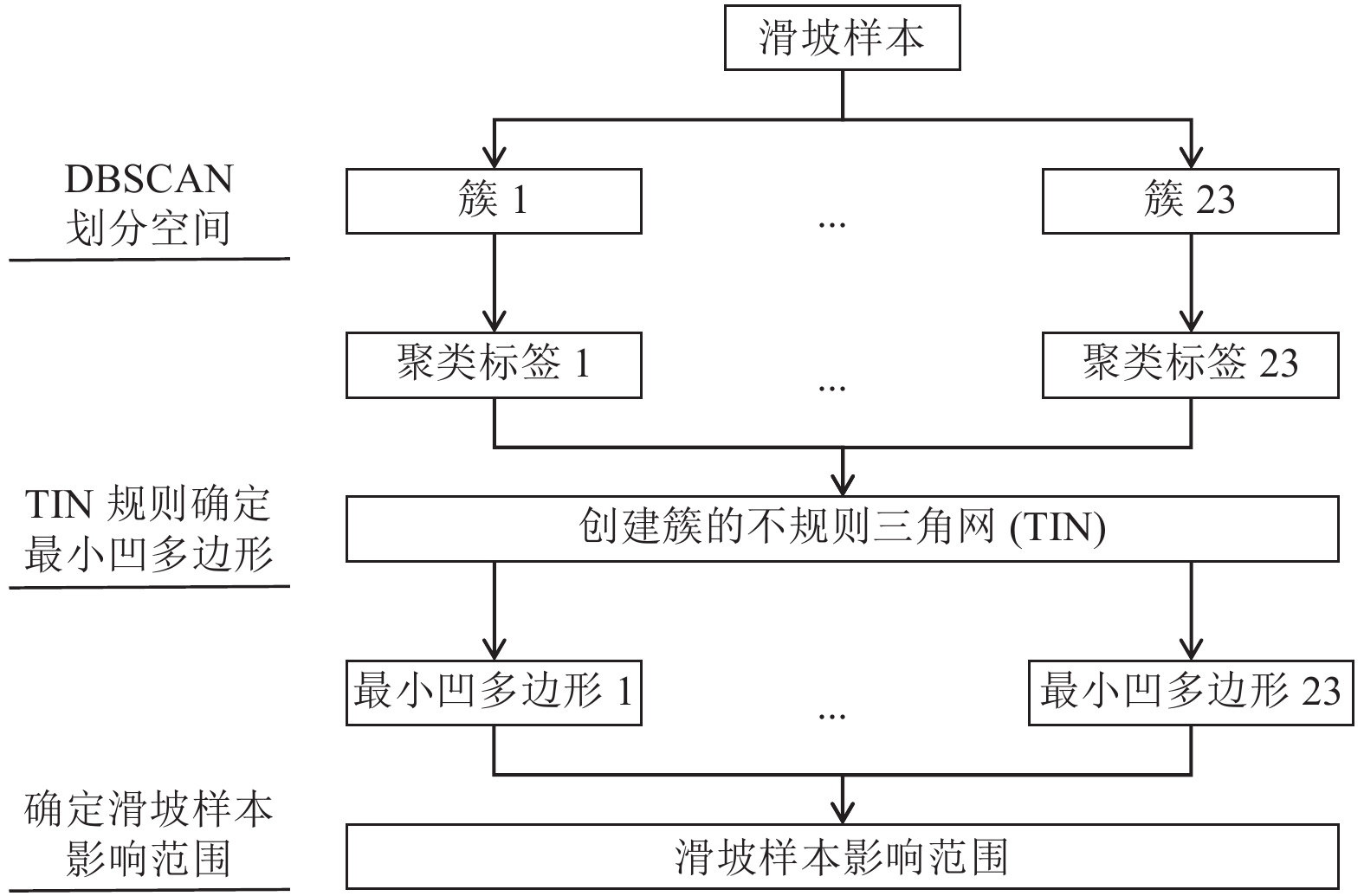
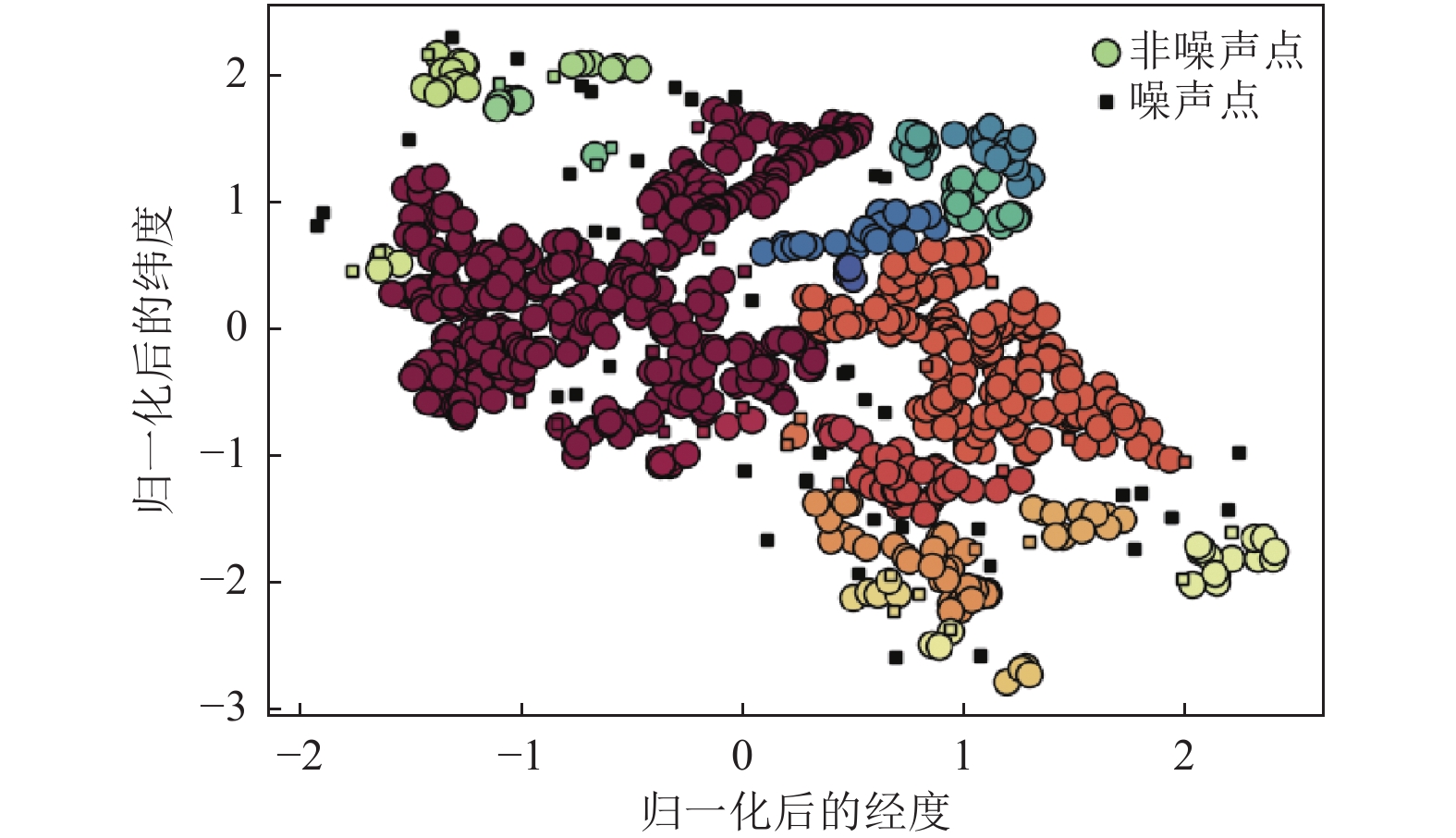
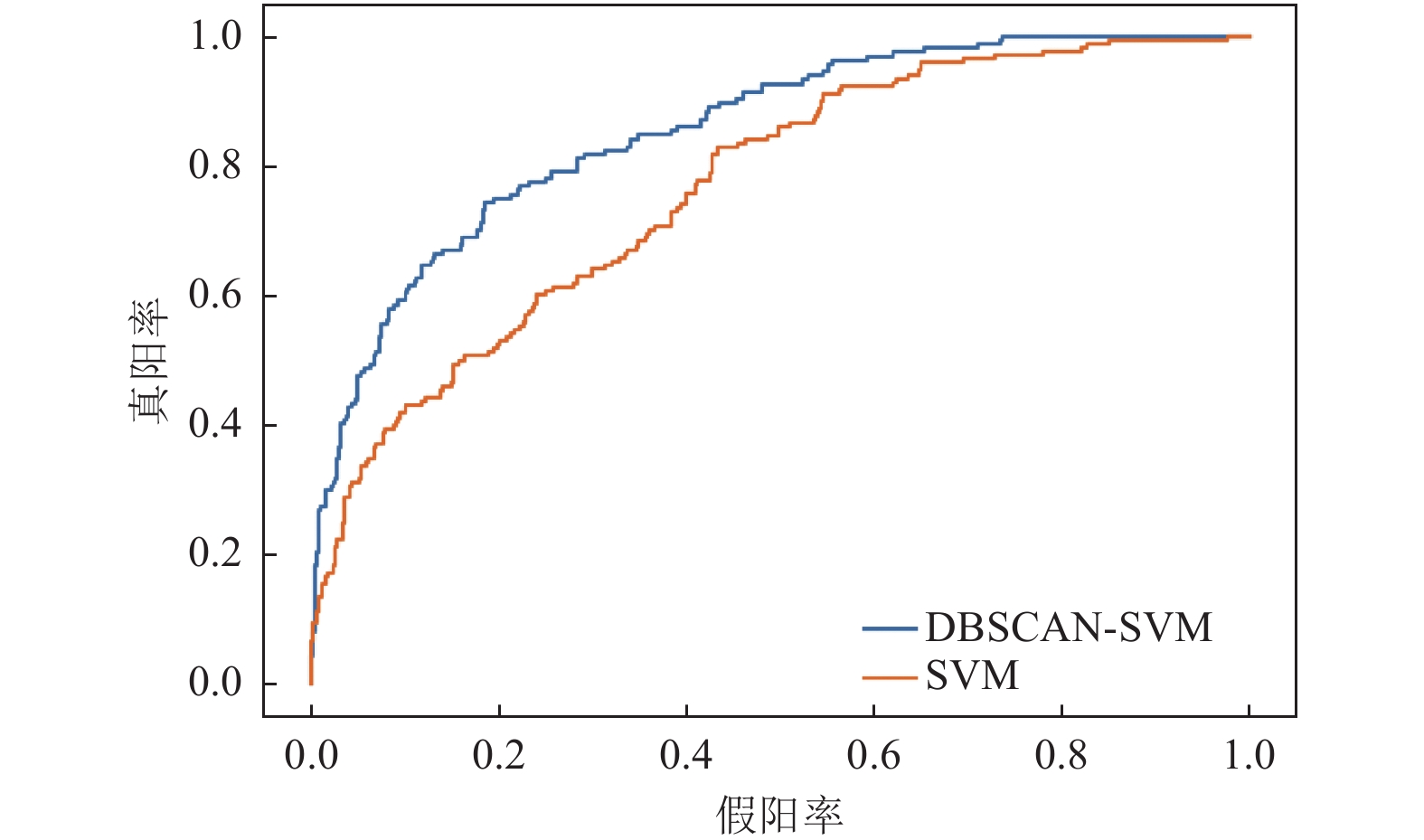
摘要: 针对基于机器学习的滑坡易发性评价中非滑坡样本选取不规范导致的分类精度较低问题,本文提出联合基于密度的噪声应用空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)采样策略和支持向量机(Support Vector Machine,SVM)分类方法的DBSCAN-SVM滑坡易发性评价模型。首先,基于DBSCAN聚类和空间分析选取非滑坡样本;然后,将样本数据代入SVM分类模型进行训练与验证,预测并提取SVM分类中属于滑坡的概率,获得滑坡易发性;最后,以四川省绵阳市为试验区,预测滑坡易发性概率,基于滑坡易发性精度与分级结果等要素,与传统非滑坡样本采集策略的SVM滑坡易发性评价模型进行对比,并结合实际情况对DBSCAN-SVM模型评价结果进行分析。研究结果表明,相比传统SVM滑坡易发性评价模型,本文提出的DBSCAN-SVM滑坡易发性评价模型在高易发区和极高易发区中包含的滑坡样本数量较多,准确率、召回率、AUC、F1分数均得到提高,精度较高。Abstract: Aiming at the problem of low classification accuracy caused by the non-standard selection of non-landslide samples in the landslide susceptibility evaluation based on machine learning, this paper proposes a combination of Density-Based Spatial Clustering of Applications with Noise (DBSCAN) sampling A DBSCAN-SVM landslide susceptibility evaluation model for strategies and Support Vector Machine (SVM) classification methods. First, non-landslide samples were selected based on DBSCAN clustering and spatial analysis; then the sample data was substituted into the SVM classification model for training and verification, the probability of landslides in the SVM classification was predicted and extracted, and the landslide susceptibility was obtained; Mianyang city is the test area, and the landslide susceptibility probability is predicted. Based on the landslide susceptibility accuracy and classification results, it is compared with the SVM landslide susceptibility evaluation model based on the traditional non-landslide sample collection strategy, and the DBSCAN-SVM is based on the actual situation. The model evaluation results are analyzed. The research results show that, compared with the traditional SVM landslide susceptibility evaluation model, the DBSCAN-SVM landslide susceptibility evaluation model proposed in this paper contains more landslide samples in high-prone areas and extremely high-prone areas, F1 scores are improved, and the accuracy is higher.
-
Key words:
- Landslide /
- Susceptibility Evaluation /
- Machine Learning /
- Clustering /
- DBSCAN /
- SVM
1) 2https://www.resdc.cn/data.aspx?DATAID=307 2) 3https://www.resdc.cn/data.aspx?DATAID=290 3) 4https://geodata.pku.edu.cn/index.php?c=content&a=show&id=877 4) 5http://www.gscloud.cn/search -
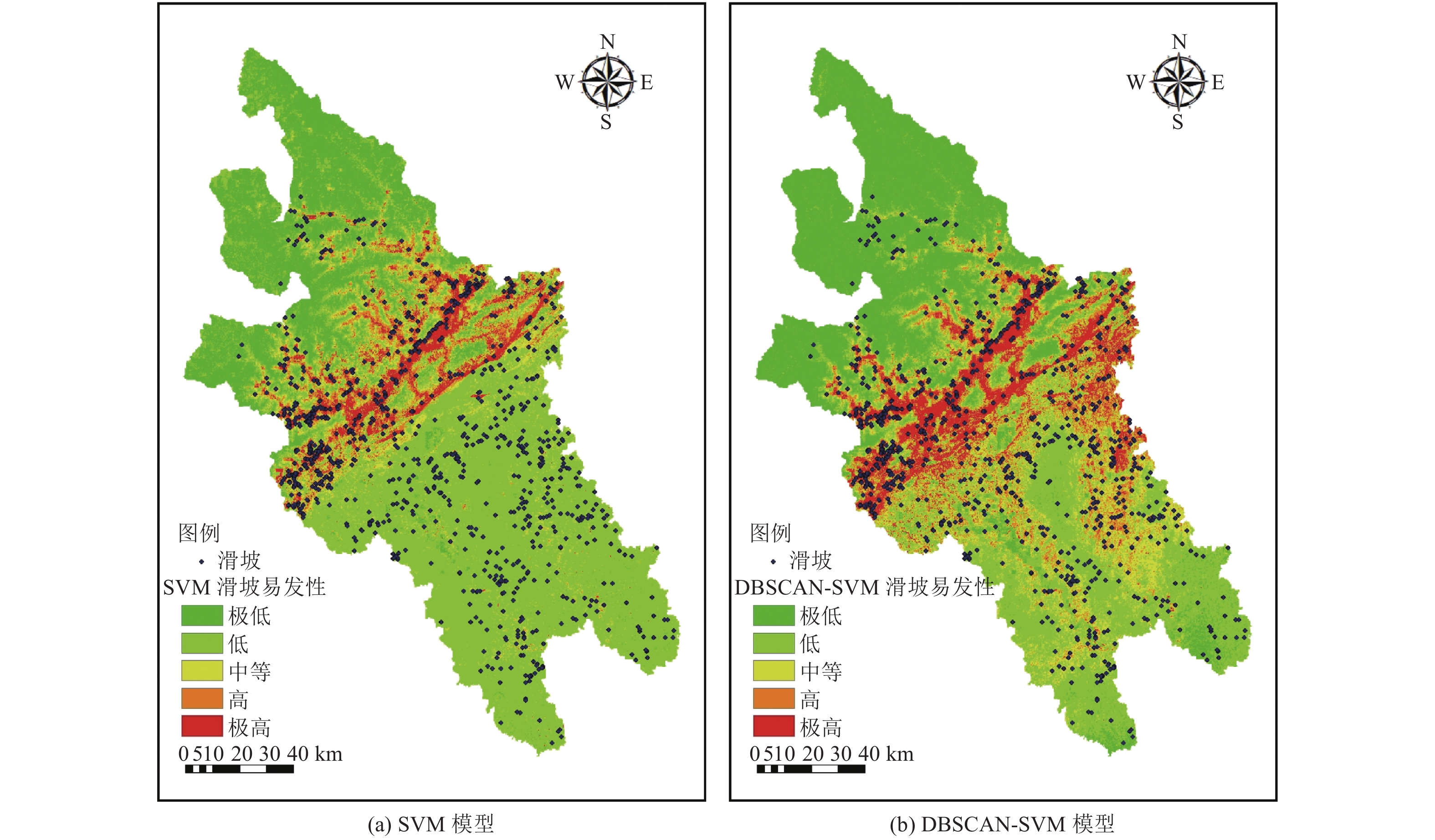
图 9 滑坡易发性自然间断点法分级图
Figure 9. Classification of natural discontinuities in landslide susceptibility
表 1 模型性能指标评价
Table 1. Model performance index evaluation
模型类型 准确率 精确率 召回率 AUC F1分数 SVM 0.794 5 0.950 6 0.810 4 0.764 3 0.874 9 DBSCAN-SVM 0.832 4 0.937 0 0.857 6 0.853 8 0.895 6  下载: 导出CSV
下载: 导出CSV
表 2 SVM模型自然间断点法分级统计结果
Table 2. SVM model natural discontinuity method classification statistics
易发性等级 栅格数 栅格比例/% 滑坡栅格数 滑坡栅格比例/% 滑坡栅格频率比 极低 4 615 695 20.50 11 1.1 0.053 7 低 12 550 678 55.75 421 42.1 0.755 2 中等 2 514 805 11.17 144 14.4 1.289 1 高 1 628 599 7.23 138 13.8 1.908 7 极高 1 202 004 5.35 286 28.6 5.345 8
下载: 导出CSV
表 4 SVM模型相等间距法分级统计结果
Table 4. SVM model equal spacing method classification statistics
易发性等级 栅格数 栅格比例/% 滑坡栅格数 滑坡栅格比例/% 滑坡栅格频率比 极低 5 778 720 25.67 16 1.6 0.062 3 低 13 266 643 58.93 516 51.6 0.875 6 中等 2 021 277 8.98 144 14.4 1.603 6 高 1 216 493 5.40 237 23.7 4.388 9 极高 228 648 1.02 87 8.7 8.529 4
下载: 导出CSV
表 3 DBSCAN-SVM模型自然间断点法分级统计结果
Table 3. DBSCAN-SVM model natural discontinuity method classification statistics
易发性等级 栅格数 栅格比例/% 滑坡栅格数 滑坡栅格比例/% 滑坡栅格频率比 极低 6 590 685 29.28 31 3.1 0.105 9 低 7 185 195 31.92 180 18.0 0.563 9 中等 4 030 995 17.91 195 19.5 1.088 8 高 2 609 423 11.59 220 22.0 1.898 2 极高 2 095 483 9.30 374 37.4 4.021 5
下载: 导出CSV
表 5 DBSCAN-SVM模型相等间距法分级统计结果
Table 5. DBSCAN-SVM model equal spacing method classification statistics
易发性等级 栅格数 栅格比例/% 滑坡栅格数 滑坡栅格比例/% 滑坡栅格频率比 极低 9 251 425 41.09 78 7.8 0.189 8 低 7 055 402 31.34 258 25.8 0.823 2 中等 3 000 187 13.33 192 19.2 1.440 4 高 2 027 977 9.01 235 23.5 2.608 2 极高 1 176 790 5.23 237 23.7 4.531 5
下载: 导出CSV
-
[1] 陈强, 田杰, 黄海宁等, 2013. 基于统计和纹理特征的SAS图像SVM分割研究. 仪器仪表学报, 34(6): 1413—1420 doi: 10.3969/j.issn.0254-3087.2013.06.031Chen Q. , Tian J. , Huang H. N. , et al. , 2013. Study on SAS image segmentation using SVM based on statistical and texture features. Chinese Journal of Scientific Instrument, 34(6): 1413—1420. (in Chinese) doi: 10.3969/j.issn.0254-3087.2013.06.031 [2] 高攀, 田浩, 李健等, 2019. 基于改进DBScan算法的雷暴挖掘与研究. 高压电器, 55(4): 169—177Gao P. , Tian H. , Li J. , et al. , 2019. Excavation and research of thunderstorm based on improved DBScan algorithm. High Voltage Apparatus, 55(4): 169—177. (in Chinese) [3] 郭果, 陈筠, 李明惠, 2013. 土质滑坡发育概率与坡度间关系研究. 工程地质学报, 21(4): 607—612 doi: 10.3969/j.issn.1004-9665.2013.04.018Guo G. , Chen J. , Li M. H. , 2013. Statistic relationship between slope gradient and landslide probability in soil slopes around reservoir. Journal of Engineering Geology, 21(4): 607—612. (in Chinese) doi: 10.3969/j.issn.1004-9665.2013.04.018 [4] 黄发明, 殷坤龙, 蒋水华等, 2018. 基于聚类分析和支持向量机的滑坡易发性评价. 岩石力学与工程学报, 37(1): 156—167Huang F. M. , Yin K. L. , Jiang S. H. , et al. , 2018. Landslide susceptibility assessment based on clustering analysis and support vector machine. Chinese Journal of Rock Mechanics and Engineering, 37(1): 156—167. (in Chinese) [5] 李文杰, 闫世强, 蒋莹等, 2019. 自适应确定DBSCAN算法参数的算法研究. 计算机工程与应用, 55(5): 1—7, 148 doi: 10.3778/j.issn.1002-8331.1809-0018Li W. J. , Yan S. Q. , Jiang Y. , et al. , 2019. Research on method of self-adaptive determination of DBSCAN algorithm parameters. Computer Engineering and Applications, 55(5): 1—7, 148. (in Chinese) doi: 10.3778/j.issn.1002-8331.1809-0018 [6] 林荣福, 刘纪平, 徐胜华等, 2020. 随机森林赋权信息量的滑坡易发性评价方法. 测绘科学, 45(12): 131—138Lin R. F. , Liu J. P. , Xu S. H. , et al. , 2020. Evaluation method of landslide susceptibility based on random forest weighted information. Science of Surveying and Mapping, 45(12): 131—138. (in Chinese) [7] 马思远, 许冲, 田颖颖等, 2019. 基于逻辑回归模型的九寨沟地震滑坡危险性评估. 地震地质, 41(1): 162—177 doi: 10.3969/j.issn.0253-4967.2019.01.011Ma S. Y. , Xu C. , Tian Y. Y. , et al. , 2019. Application of logistic regression model for hazard assessment of earthquake-triggered landslides: a case study of 2017 Jiuzhaigou (China) MS7.0 event. Seismology and Geology, 41(1): 162—177. (in Chinese) doi: 10.3969/j.issn.0253-4967.2019.01.011 [8] 王毅, 方志策, 牛瑞卿等, 2021. 基于深度学习的滑坡灾害易发性分析. 地球信息科学学报, 23(12): 2244—2260 doi: 10.12082/dqxxkx.2021.210057Wang Y. , Fang Z. C. , Niu R. Q. , et al. , 2021. Landslide susceptibility analysis based on deep learning. Journal of Geo-Information Science, 23(12): 2244—2260. (in Chinese) doi: 10.12082/dqxxkx.2021.210057 [9] 吴玮莹, 王晓青, 邓飞, 2017. 基于高分卫星遥感影像的地震应急滑坡编目与分布特征探讨——以2017年8月8日九寨沟7.0级地震为例. 震灾防御技术, 12(4): 815—825Wu W. Y., Wang X. Q., Deng F., 2017. Compilation and spatial analysis of co-seismic landslide inventory by using high-resolution remote sensing images in earthquake emergency response: an example of the Jiuzhaigou MS7.0 earthquake on August 8, 2017. Technology for Earthquake Disaster Prevention, 12(4): 815—825. (in Chinese) [10] 武雪玲, 沈少青, 牛瑞卿, 2016. GIS支持下应用PSO-SVM模型预测滑坡易发性. 武汉大学学报·信息科学版, 41(5): 665—671Wu X. L, Shen S. Q. , Niu R. Q. , 2016. Landslide susceptibility prediction using GIS and PSO-SVM. Geomatics and Information Science of Wuhan University, 41(5): 665—671. (in Chinese) [11] 徐胜华, 刘纪平, 王想红等, 2020. 熵指数融入支持向量机的滑坡灾害易发性评价方法——以陕西省为例. 武汉大学学报·信息科学版, 45(8): 1214—1222Xu S. H. , Liu J. P. , Wang X. H. , et al. , 2020. Landslide susceptibility assessment method incorporating index of entropy based on support vector machine: a case study of Shaanxi province. Geomatics and Information Science of Wuhan University, 45(8): 1214—1222. (in Chinese) [12] Kavzoglu T. , Sahin E. K. , Colkesen I. , 2014. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides, 11(3): 425—439. doi: 10.1007/s10346-013-0391-7 [13] Liu M. M. , Liu J. P. , Xu S. H. , et al. , 2021. Landslide susceptibility mapping with the fusion of multi-feature SVM model based FCM sampling strategy: a case study from Shaanxi Province. International Journal of Image and Data Fusion, 12(4): 349—366. doi: 10.1080/19479832.2021.1961316 [14] Peng L. , Niu R. Q. , Huang B. , et al. , 2014. Landslide susceptibility mapping based on rough set theory and support vector machines: a case of the Three Gorges area, China. Geomorphology, 204: 287—301. doi: 10.1016/j.geomorph.2013.08.013 [15] Vapnik V. N., 1995. The nature of statistical learning theory. New York: Springer. -
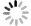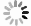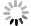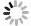



 点击查看大图
点击查看大图

计量
- 文章访问数: 356
- HTML全文浏览量: 78
- PDF下载量: 39
- 被引次数: 0
