
Fast Extraction Method of Building Characteristics for Earthquake Catastrophe Insurance
-
摘要: 房屋建筑分类是抗震设计和地震风险分析的基础,是巨灾保险的纽带环节,也是结构易损性准确、完备分析的前驱保障,快速获取建筑特性参数非常关键。基于影像数据获取结构特性相比传统手段具有显著优势,然而其准确性具有一定挑战性,从影像数据得到实时的、较准确的结构特性成为地震保险数据获取技术的关注焦点。本文采用深度学习方法开展从影像数据中提取面向地震保险需求的建筑特性数据,构建基于深度学习方法的建筑高度识别模型和基于机器视觉的建筑高度识别方法,运用基于Xception神经网络深度学习和机器视觉的模型,对北京地区的建筑高度进行模型测试,该方法可为地震保险分析提供重要的基础数据支持。Abstract: Building classification is the basis of seismic design and earthquake risk analysis, and is also the link of catastrophe insurance. It is also the precursor to the accurate and complete analysis of structural vulnerability, and it is critical to quickly obtain building characteristic parameters. Obtaining structural characteristics based on image data has significant advantages over traditional methods. However, the accuracy of its related methods is a very challenging problem. Obtaining more accurate structural characteristics from image data in real time has become the focus of seismic insurance data acquisition technology. In this paper, deep learning method is used to extract building characteristic data oriented to earthquake insurance from image data. Building height recognition model based on deep learning methods were performed and applied in Beijing. The method can provide important basic data support for earthquake insurance analysis.
-
Key words:
- Earthquake /
- Catastrophe insurance /
- Building characteristics /
- Information extraction
-
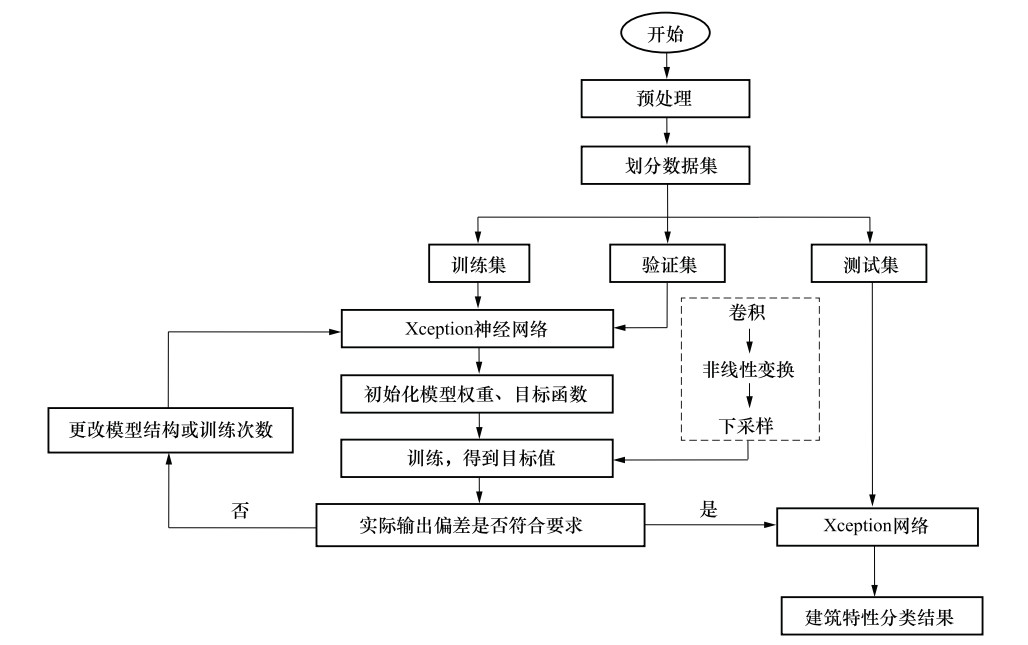
图 2 Xception神经网络模型识别建筑信息处理流程图
Figure 2. Xception neural network model recognition building information processing flow chart
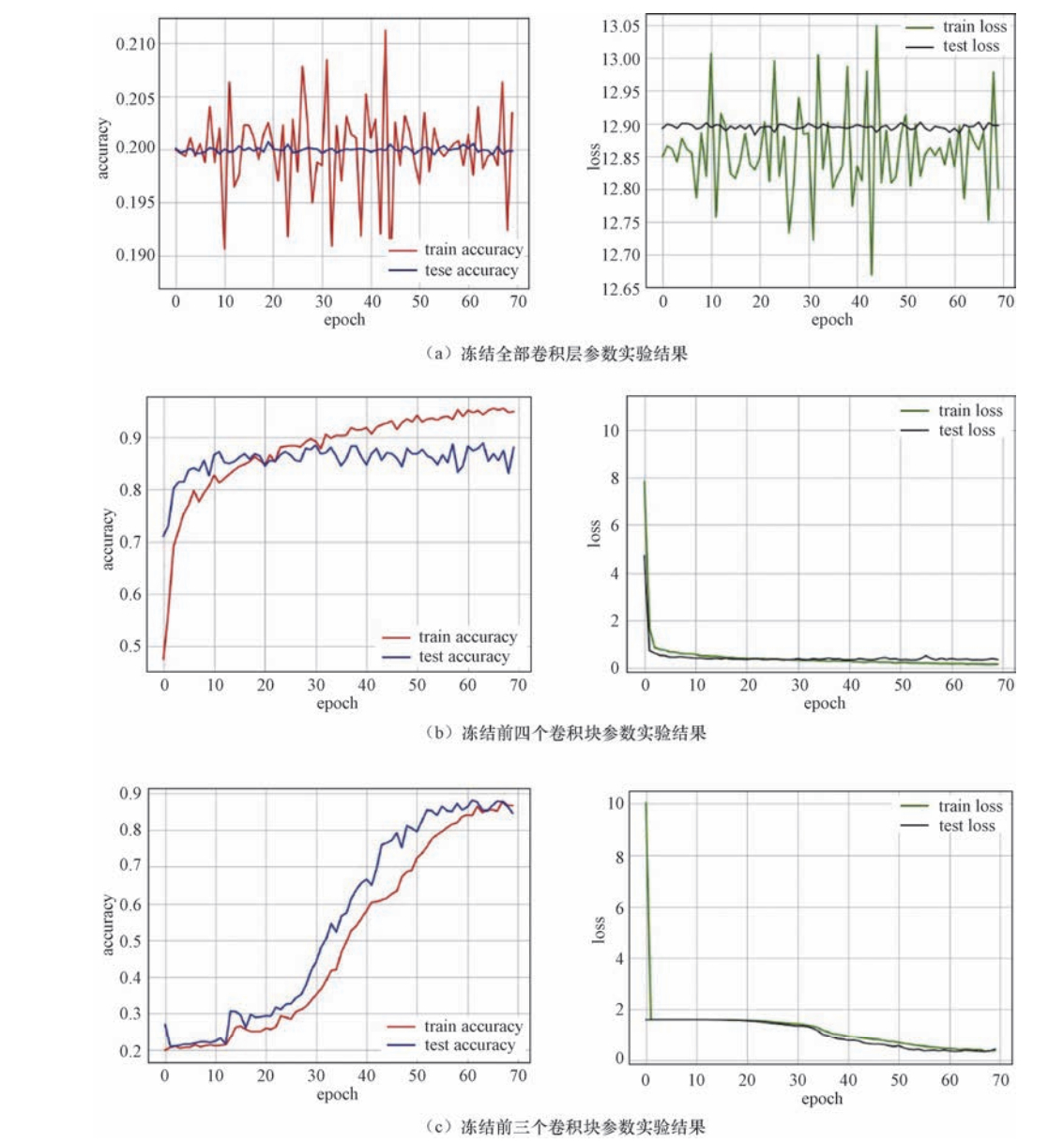
图 3 冻结不同层参数实验结果
Figure 3. The experimental results of freezing different layer parameters
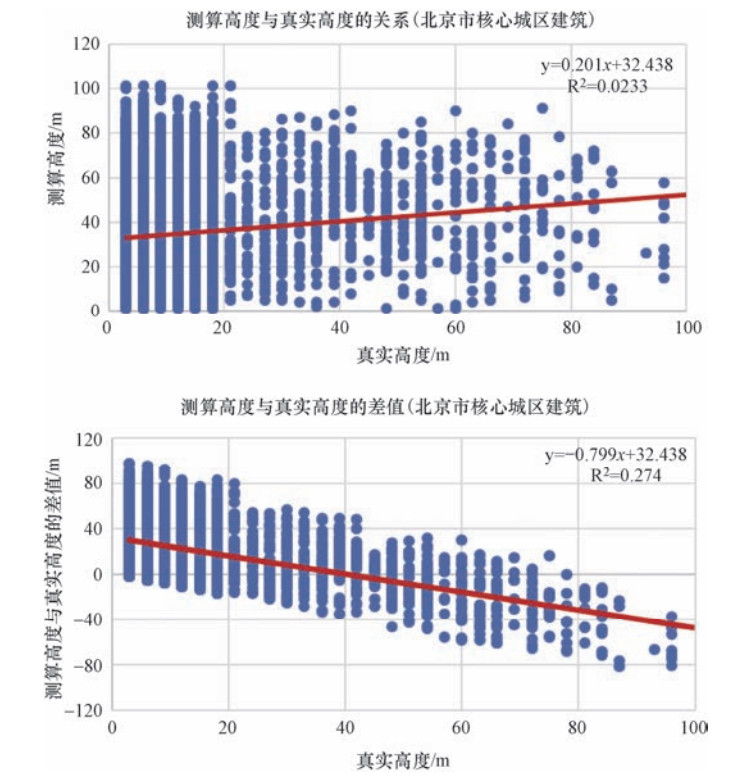
图 4 模型测算高度与真实高度的相关性和误差(北京市核心域区建筑)
Figure 4. The correlation and error between the model's measured height and the true height (Beijing's core urban area)
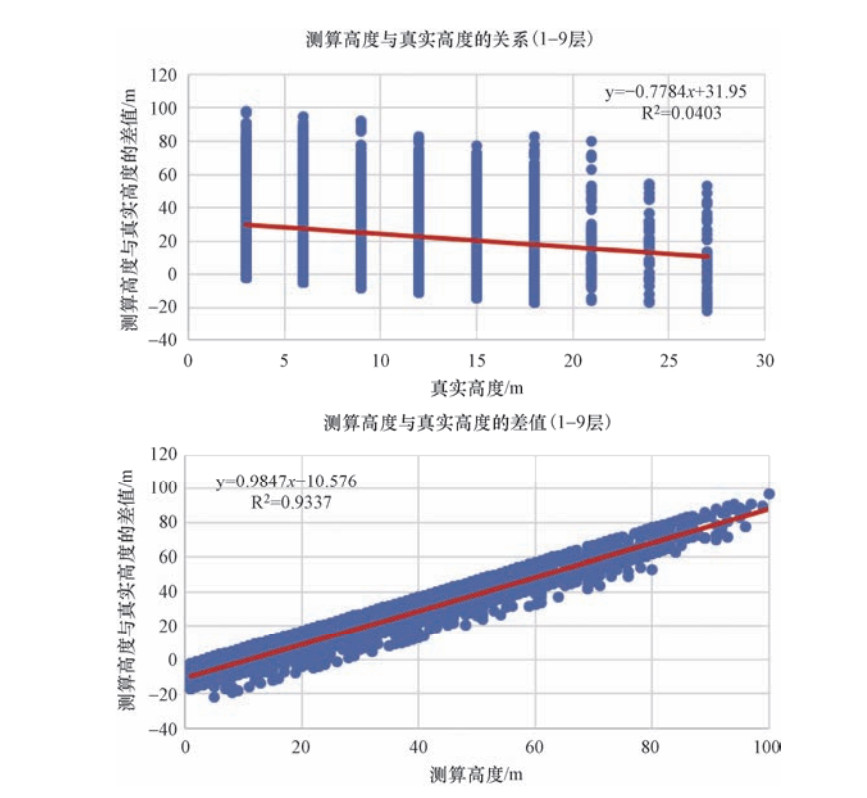
图 5 模型测算高度与真实高度的相关性和误差(1-9层)
Figure 5. The correlation and error of the model's measured height and the true height (1-9 layers)
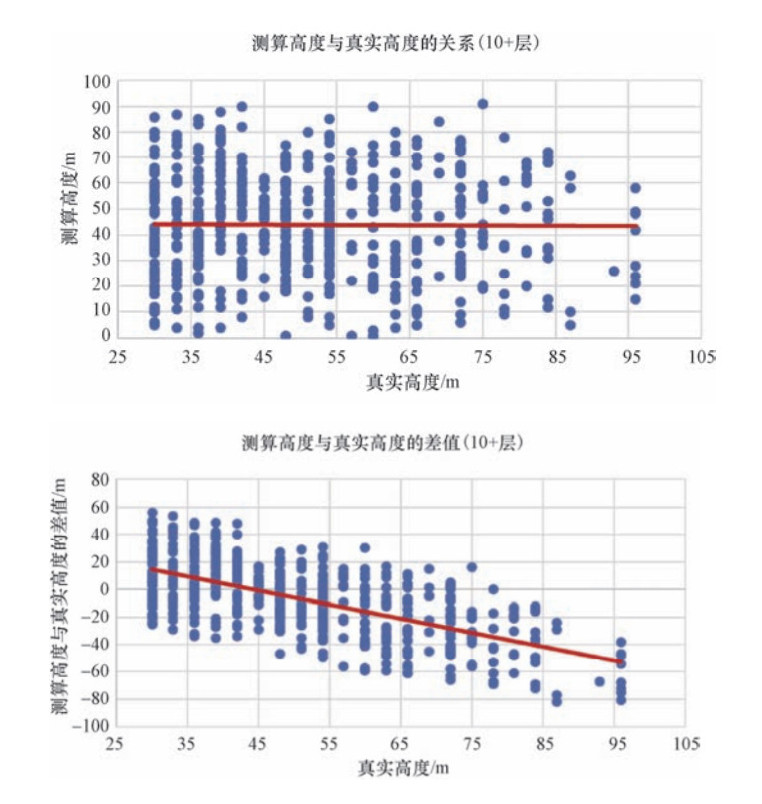
图 6 模型测算高度与真实高度的相关性和误差(10层及以上)
Figure 6. The correlation and error of the model's measured height and the true height (above 10 layers)
表 1 冻结不同卷积层参数计算结果
Table 1. The experimental results of freezing different layer parameters
冻结层数 每次迭代时间/s 测试集误差 测试准确度 测试误差变化趋势 冻结全部卷积层参数 37 网络发散 — — 冻结前四层卷积层参数 36 0.4400 0.8342 在40次迭代后趋于稳定 冻结前三层卷积层参数 37 0.4189 0.8459 在60次迭代后趋于稳定  下载: 导出CSV
下载: 导出CSV
-
杜浩国, 张方浩, 邓树荣等, 2018. 震后极灾区无人机最优航拍区域选择. 地震研究, 41(2): 209-215. doi: 10.3969/j.issn.1000-0666.2018.02.008 李金香, 赵朔, 金花等, 2019. 结合纹理和形态学特征的高分遥感影像建筑物震害信息提取. 地震学报, 41(5): 658-670. https://www.cnki.com.cn/Article/CJFDTOTAL-DZXB201905008.htm 李强, 张景发, 2016. 不同特征融合的震后损毁建筑物识别研究. 地震研究, 39(3): 486-493. doi: 10.3969/j.issn.1000-0666.2016.03.018 夏浩铭, 罗金辉, 雷利元等, 2012. 辅以纹理和BP神经网络的TM遥感影像分类. 地理空间信息, 10(1): 33-36. doi: 10.3969/j.issn.1672-4623.2012.01.012 Bengio Y., Simard P., Frasconi P., 1994. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2): 157-166. doi: 10.1109/72.279181 Bengio Y., Delalleau O., Le Roux N., 2005. The curse of highly variable functions for local kernel machines. In: Proceedings of the 18th International Conference on Neural Information Processing Systems. Vancouver, British Columbia: MIT Press, 107-114. Choi J., Yoo Y. J., Choi J. Y., 2010. Adaptive shadow estimator for removing shadow of moving object. Computer Vision and Image Understanding, 114(9): 1017-1029. doi: 10.1016/j.cviu.2010.06.003 Ciodaro T., Deva D., de Seixas J. M., et al., 2012. Online particle detection with neural networks based on topological calorimetry information. Journal of Physics: Conference Series, 368(1): 012030. http://iopscience.iop.org/1742-6596/368/1/012030?rel=ref&relno=6 Farabet C., Couprie C., Najman L., et al., 2013. Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8): 1915-1929. doi: 10.1109/TPAMI.2012.231 Helmstaedter M., Briggman K. L., Turaga S. C., et al., 2013. Connectomic reconstruction of the inner plexiform layer in the mouse retina. Nature, 500(7461): 168-174. doi: 10.1038/nature12346 Hinton G., Deng L., Yu D., et al., 2012. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Processing Magazine, 29(6): 82-97. doi: 10.1109/MSP.2012.2205597 Jiang C. X., Ward M. O., 1994. Shadow segmentation and classification in a constrained environment. CVGIP: Image Understanding, 59(2): 213-225. doi: 10.1006/ciun.1994.1014 Krizhevsky A., Sutskever I., Hinton G. E., 2012. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1. Lake Tahoe, Nevada: Curran Associates Inc. Le Cun Y., Boser B., Denker J. S., et al., 1990. Handwritten digit recognition with a back-propagation network. In: Touretzky D. S., ed., Advances in Neural Information Processing Systems 2. San Francisco CA: Morgan Kaufmann Publishers Inc., 396-404. Ma J. S., Sheridan R. P., Liaw A., et al., 2015. Deep neural nets as a method for quantitative structure-activity relationships. Journal of Chemical Information and Modeling, 55(2): 263-274. doi: 10.1021/ci500747n Mikolov T., Deoras A., Povey D., et al., 2011. Strategies for training large scale neural network language models. In: Proceedings of 2011 IEEE Workshop on Automatic Speech Recognition & Understanding. Waikoloa: IEEE, 196-201. Sainath T. N., Mohamed A. R., Kingsbury B., et al., 2013. Deep convolutional neural networks for LVCSR. In: Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, BC: IEEE, 8614-8618. Szegedy C., Liu W., Jia Y. Q., et al., 2014. Going deeper with convolutions. In: Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE. Tompson J., Jain A., LeCun Y., et al., 2014. Joint training of a convolutional network and a graphical model for human pose estimation. In: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1. Montreal, Canada: MIT Press, 1799-1807. -
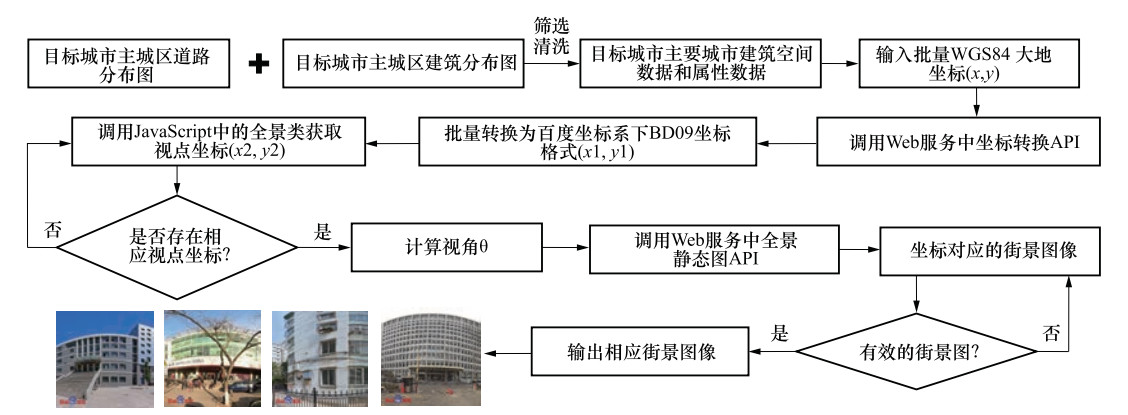
 点击查看大图
点击查看大图
计量
- 文章访问数: 162
- HTML全文浏览量: 79
- PDF下载量: 7
- 被引次数: 0
