
Optimizing Information Coding of Active Fault Survey Data
-
摘要: 从20世纪90年代起,研究人员就开始探索活动断层探察数据的制作、存储与管理。迄今为止,已经获得了大量的活动断层探察数据,建成了一套系统的数据组织体系,为减轻地震灾害的相关研究提供了数据和技术支撑。近年来,随着活动断层数据库信息的扩充,初期设计的部分属性信息编码已不适用。为了形成适应当前工作的属性信息编码体系,本文以活动断层数据库建设体系为基础,对数据库属性值代码进行信息分类和编码优化。文章将数据库属性值代码分为字符型单一含义值、数值型单一含义值及复合含义值,分别进行编码规则设计,最终优化了数据库属性信息编码体系,提高了从建库到数据应用的数据录入、检测、制图自动化、数据分析等环节的效率。Abstract: The study of digital active fault database of storing and managing active fault survey data started in the 1990s. In the following 20 years, a systematic database framework has been developed, which provided fundamental data to minimize losses caused by earthquake disasters. In recent years, as the database framework developed and the range of information extended, some early designed attribute value codes are no longer adaptable to the new database framework. In order to build a more applicable attribute value coding system, we designed the coding rules respectively for three types of values: simple meaning character codes, simple meaning numerical codes and complex meaning codes. A new attribute value coding system has been built and discussed in this paper. The results show that the new system is helpful of increasing the efficiency of data entry, data detection, auto-mapping, data analysis and other relevant work.
-
Key words:
- Active fault /
- Database /
- Information classification /
- Information coding /
- Survey data /
- Optimize
-
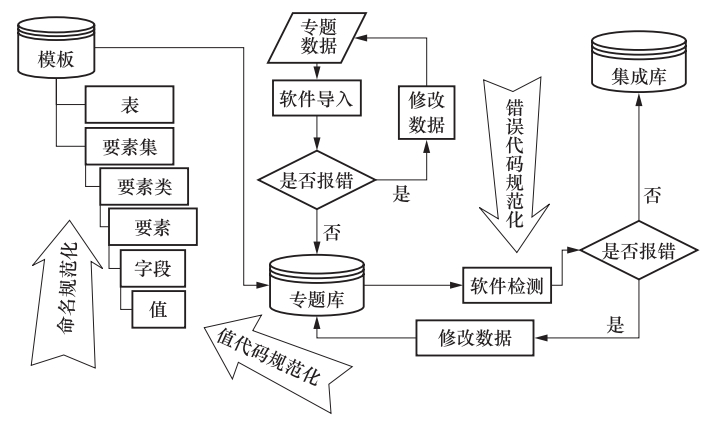
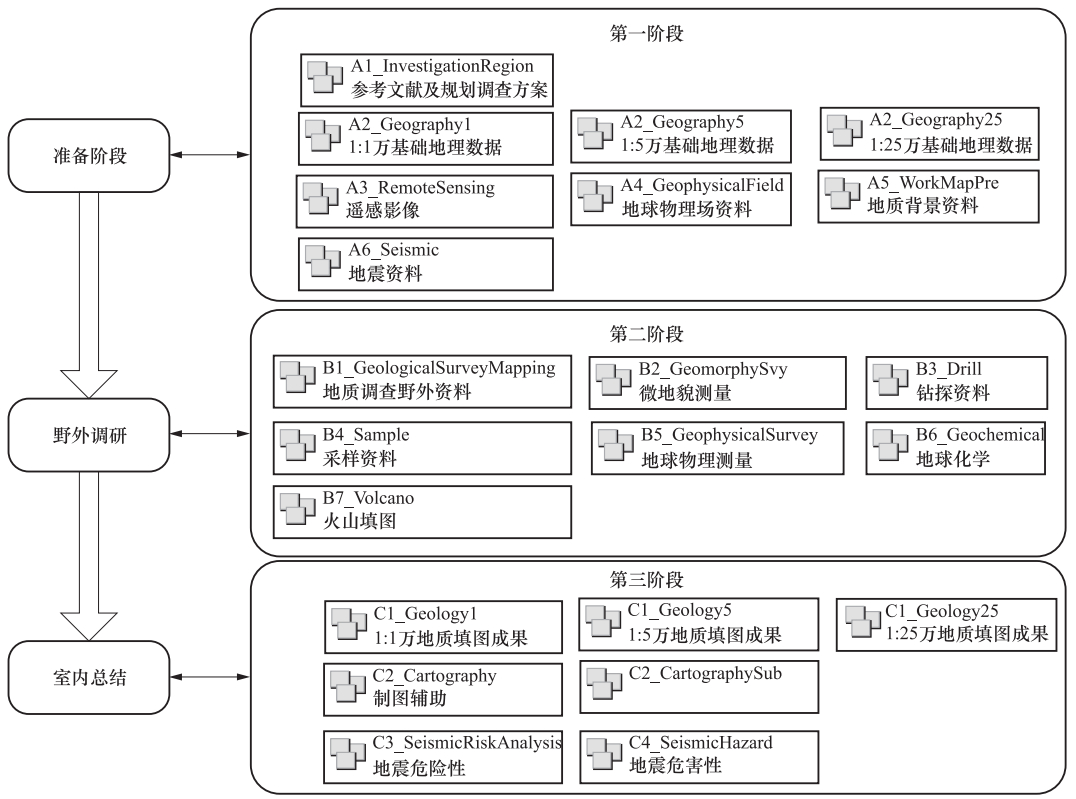
图 1 规范化在数据库建设各环节中的示意图
Figure 1. Abridged general view of standardization in building Active Fault Database

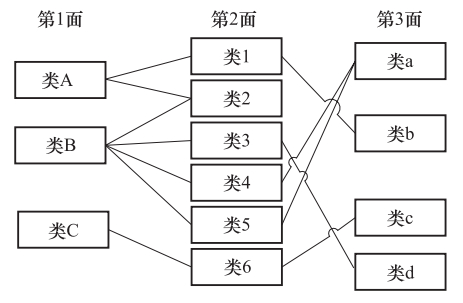
图 4 数据组织第二层面:以断层数据为例
Figure 4. The second dimension of data structure: a case of fault data
表 1 表示数据来源的值代码表
Table 1. Codes of data sources
值域名称 值 代码 样品数据来源 野外地质调查点 GSP 探槽 TC 钻孔 DL 微地貌测量 GS 目标破裂带来源 1:10 000地震地表破裂带(FractureBelt1) FB1 1:50 000地震地表破裂带(FractureBelt5) FB5 1:250 000断裂地震地表破裂带(FractureBelt25) FB25 目标断层来源 1:10 000断层(Fault1) F1 1:50 000断裂(Fault5) F5 1:250 000断裂(Fault25) F25 活动断层(ActiveFault) AF 采样情况说明 一种样品单次采样 STSS 一种样品多次采样 STMS 多种样品多次采样 MTMS  下载: 导出CSV
下载: 导出CSV
表 2 单一含义数值型代码表
Table 2. Codes of simple numerical value
值域名称 描述值 代码 方位角(16方位) E 90 NEE 75 NE 45 NNE 15 N 0 NNW 345 NW 315 NWW 285 W 270 SWW 255 SW 225 SSW 195 S 180 SSE 165 SE 135 SEE 105 可靠性等级 Excellent 5 Good 4 Normal 3 Poor 2 Fail 1
下载: 导出CSV
表 3 地质年代代码表
Table 3. Code values of geological times
年代 代码 Qh3 33320300 Qh2-3 33320230 Qh2 33320200 Qh1-2 33320120 Qh1 33320100 Qh 33320000 Qp3-Qh 33312300 Qp32 33310302 Qp31 33310301 Qp3 33310300 Qp2 33310200 Qp1+2 33310120 Qp1 33310100 Qp 33310000 Q 33300000 Pre-Q -33300000 N22 33220200 N21 33220100 N2 33220000 N14 33210400 N13 33210300 N12 33210200 N11 33210100 N1 33210000 N 33200000 E32 33130200 E31 33130100 E3 33130000 E24 33120400 E23 33120300 E22 33120200 E21 33120100 E2 33120000 E12 33110200 E11 33110100 E1 33110000 E 33100000 Cz 33000000 AnR -33000000 K1 32310000 K 32300000 T1 32110000 T 32100000 Mz 32000000 Pre-Mz -32000000 P2 31620000 P1 31610000 P 31600000 C1 31510000 C 31500000 D2 31420000 D1 31410000 D 31400000 S4 31340000 S3 31330000 S2 31320000 S1 31310000 S 31300000 O3 31230000 O21 31220100 O2 31220000 O1 31210000 O 31200000 ∈3 31130000 ∈2 31120000 ∈1 31110000 ∈ 31100000 Pre-∈ -31100000 Pz 31000000 PH 30000000 Z2 23320000 Z1 23310000 Z 23300000 Nh2 23220000 Nh1 23210000 Nh 23200000 Qb2 23120000 Qb1 23110000 Qb 23100000 Pt3 23000000 Jx2 22220000 Jx1 22210000 Jx 22200000 Ch2 22120000 Ch1 22110000 Ch 22100000
下载: 导出CSV
表 4 岩体形成时期代码表
Table 4. Codes of rock formation times
年代 代码 喜马拉雅期(古近纪-第四纪) 33103330 燕山期(侏罗纪-白垩纪) 32203230 印支期(三叠纪) 32100000 华力西期(泥盆纪-二叠纪) 31403160 加里东期(寒武纪-志留纪) 31103130 震旦期(南华纪-震旦纪) 23202330 晋宁期(青白口纪) 23000000 四堡期(中元古代) 22000000 吕梁期(古元古代) 21000000 前吕梁期(太古宙) 10000000
下载: 导出CSV
表 6 第3 — 6位代码含义概况表
Table 6. Description of the third to sixth characters of code
大类 小类 复合含义6位数值型代码的第3—6位含义 地质 实体 第3位实体名代码 第4、5、6位内部编码 描述 第3位描述参数代码 地球物理 实体 第3、4位实体名代码 第5、6位保留 方法 第3、4位探测方法代码 第5、6位内部编码 状态 第3、4位保留 第5、6位表示状态 地球化学 方法 第3、4位探测方法代码 第5、6位表示探测方法 样品 方法 第3、4位测试方法代码 第5、6位内部编码 火山 实体 第3位实体名称代码 第4、5、6位内部编码
下载: 导出CSV
表 7 断层类型代码表
Table 7. Codes of different fault types
值 代码 出露性质未知 111100 走滑 111101 左旋 111102 右旋 111103 正断 111110 走滑正断 111111 左旋正断 111112 右旋正断 111113 逆断 111120 走滑逆断 111121 左旋逆断 111122 右旋逆断 111123 隐伏性质未知 111200 隐伏走滑 111201 隐伏左旋 111202 隐伏右旋 111203 隐伏正断 111210 隐伏走滑正断 111211 隐伏左旋正断 111212 隐伏右旋正断 111213 隐伏逆断 111220 隐伏走滑逆断 111221 隐伏左旋逆断 111222 隐伏右旋逆断 111223 推测性质未知 111300 推测走滑 111301 推测左旋 111302 推测右旋 111303 推测正断 111310 推测走滑正断 111311 推测左旋正断 111312 推测右旋正断 111313 推测逆断 111320 推测走滑逆断 111321 推测左旋逆断 111322 推测右旋逆断 111323
下载: 导出CSV
-
崔瑾, 柴炽章, 王银, 2014.活断层数据库建设技术方法及操作综述.震灾防御技术, 9(2):271-279. doi: 10.11899/zzfy20140212 董曼, 杨天青, 2014.地震应急灾情信息分类探讨.震灾防御技术, 9(4):937-943. doi: 10.11899/zzfy20140423 葛孚刚, 王冬雷, 王志才等, 2011.山东省1:20万活断层数据库建设.土工基础, 25(3):64-67. http://www.cnki.com.cn/Article/CJFDTOTAL-TGJC201103021.htm 葛伟鹏, 袁道阳, 郭华, 2006.对城市活断层探测项目中地震地质数据建模的探讨.西北地震学报, 28(2):134-139. http://www.cnki.com.cn/Article/CJFDTOTAL-ZBDZ200602007.htm 李策, 杜云艳, 于贵华等, 2008.基于ArcGIS的地震活断层多源数据组织与管理研究.地球信息科学, 10(6):716-723. http://www.cnki.com.cn/Article/CJFDTOTAL-DQXX200806007.htm 李新通, 何建邦, 毕建涛, 2002.国家资源环境数据库信息分类编码及应用模式.地理学报, 57(S):9-17. http://cdmd.cnki.com.cn/Article/CDMD-10759-1016181552.htm 刘娜, 张建国, 毛燕等, 2009.活断层数据库在昆明市防震减灾工作中的应用研究.地震研究, 32(S):503-506. http://cdmd.cnki.com.cn/Article/CDMD-11415-2007066981.htm 柔洁, 刘云华, 傅长海, 2008.乌鲁木齐市活断层数据库在城市建设中的作用.内陆地震, 22(3):193-202. http://www.cnki.com.cn/Article/CJFDTOTAL-LLDZ200803002.htm 田胜清, 2006.核电厂地震安全性评价中的断裂构造调查与评价.震灾防御技术, 1(1):25-30. doi: 10.11899/zzfy20060104 徐锡伟, 于贵华, 马文涛等, 2002.活断层地震地表破裂"避让带"宽度确定的依据与方法.地震地质, 24(4):470-483. http://www.cnki.com.cn/Article/CJFDTOTAL-DZDZ200204001.htm 徐锡伟, 2006.活动断层、地震灾害与减灾对策问题.震灾防御技术, 1(1):7-14. doi: 10.11899/zzfy20060102 于贵华, 邓起东, 邬伦等, 1996.利用GIS系统建立中国活动断裂信息咨询分析系统.地震地质, 18(2):156-160. http://www.cnki.com.cn/Article/CJFDTOTAL-DZDZ602.007.htm 于贵华, 徐锡伟, 孙怡等, 2006.城市活断层探测信息系统的设计与实现——以福州市活断层信息管理系统为例.地震地质, 28(4):655-662. http://www.cnki.com.cn/Article/CJFDTOTAL-DZDZ200604012.htm 于贵华, 杜克平, 徐锡伟, 吴熙彦, 2012.活动构造数据库建设相关问题的研究.地震地质, 34(4):713-725. http://www.cnki.com.cn/Article/CJFDTOTAL-DZDZ201204017.htm 中国地震局震害防御司, 2013.地下搞清楚:中国地震活动断层探察.防灾博览, (4):20-25. http://www.cnki.com.cn/Article/CJFDTOTAL-FZBL201304011.htm 张翼, 唐姝娅, 王悦等, 2016.地震应急信息产品分类编码研究.震灾防御技术, 11(1):132-143. doi: 10.11899/zzfy20160115 -

 点击查看大图
点击查看大图
计量
- 文章访问数: 147
- HTML全文浏览量: 49
- PDF下载量: 13
- 被引次数: 0
